1. Abre as developer tools do teu browser (tecla F12) e abre o tab "Network"
2. Abre a página de um user
3. Faz scroll para baixo, vão aparecer linhas novas na tab network
4. Quando chegares ao fim da lista, clica em cada uma das linhas e à direita faz copy do campo "data" (v. img), e cola o resultado num editor de texto
5. Repete pra todas e grava o texto como videos.txt
Agora no terminal, vai ao dir onde tens o videos.txt para podermos extrair o identificador de cada vídeo encontrado
cat videos.txt | grep randname | cut -c 17-36 > randnames.txte agora podemos descarregar tudo de uma vez com o yt-dlp:
while read p; do yt-dlp "http://videos.sapo.pt/$p"; done < randnames.txtE deve dar, ou não. Apontei isto a correr para não perder a referência, e porque não tenho tempo de escrever um scraper. Talvez dê jeito a alguém.
Obrigado @brunomiguel e @JD557@JD557 pelas pistas!
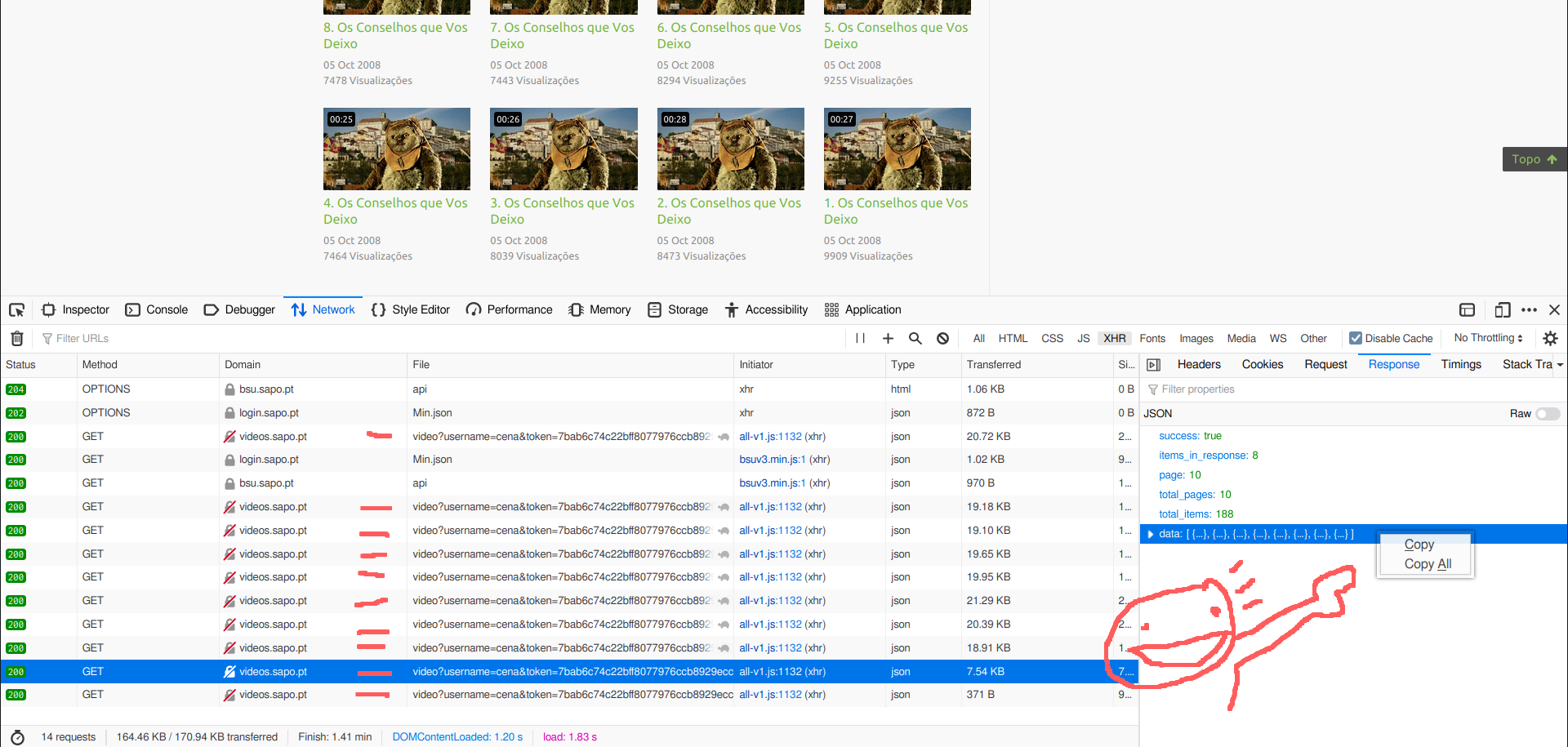 developer tools do firefox a mostrar uma response e o campo JSON a copiar
developer tools do firefox a mostrar uma response e o campo JSON a copiar