# I am the Watcher. I am your guide through this vast new twtiverse.
#
# Usage:
# https://watcher.sour.is/api/plain/users View list of users and latest twt date.
# https://watcher.sour.is/api/plain/twt View all twts.
# https://watcher.sour.is/api/plain/mentions?uri=:uri View all mentions for uri.
# https://watcher.sour.is/api/plain/conv/:hash View all twts for a conversation subject.
#
# Options:
# uri Filter to show a specific users twts.
# offset Start index for quey.
# limit Count of items to return (going back in time).
#
# twt range = 1 1
# self = https://watcher.sour.is/conv/puo3spq
OpenAI o1 self-play RL 技术路线推演**
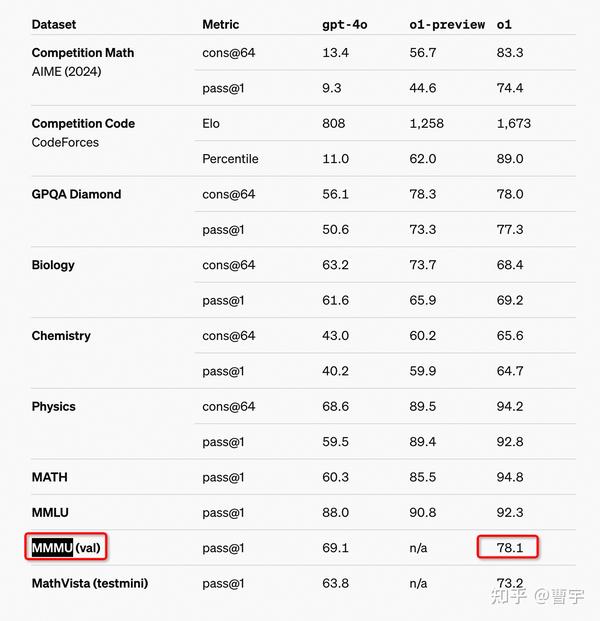
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。在数理推理领域获得了傲人的成绩,同时提出了train-time compute和test-time compute两个全新的RL scaling law。作为领域博主,在时效性方面肯定卷不过其他营销号了,所以这次准备了大概一万字的内容,彻底深入分析并推演一遍其中的相关技术细节。
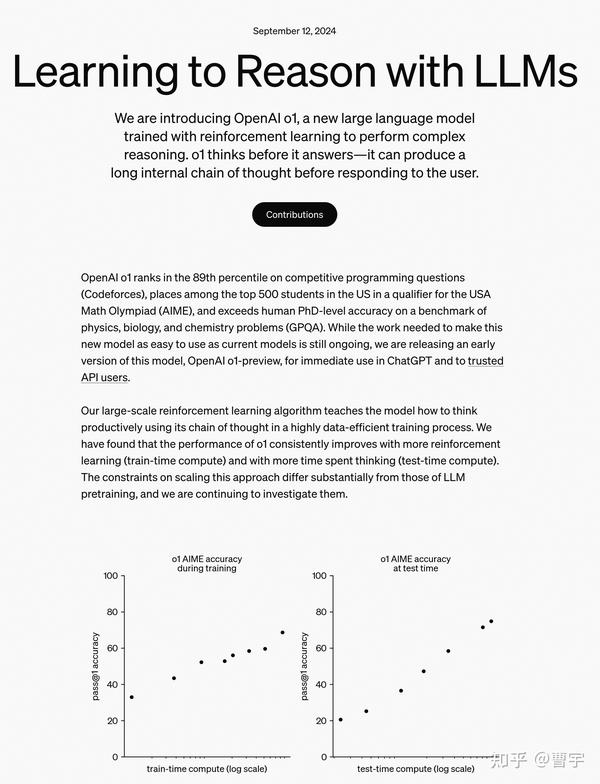
## o1,而今迈步从头越
首先要说一下,o1是一个多模态模型,很多人包括 Jim Fan 都忽略了这一点:
因此他继续叫做o,作为omni系列是没有任何疑问的。只不过这次发布是过于低调了,很多人都没有注意到 ... ⌘ Read more